
Scott Auge
Third Edition for
Webspeed 2.1
Comments: sauge@amduus.com
http://www.amduus.com
Introduction:
This book is written for working programmers. Since these people are busy, and I suspect they are like myself – very little time and lots to do, the book will be written with that in mind. So to keep the content down to under 100 pages, the following is assumed of the reader a familairity of HTML and Javascript (or VBScript).
The book will focus on stateless programming for Webspeed. This is the most inexpensive means of programming regarding licensing issues, and the most typical for web based programming. This volumn will also be interested in setting the basic elements of Webspeed needed to get rolling. Volumn II will work on state-based programming with Webspeed.
Readers who are familiar with HTML 3.2+ and Javascript will benefit quite well. If you do not understand HTML and Javascript, you had better go get a book on that NOW! Webspeed pretty much does away with all the Progress 4GL statements to format screen layout. In fact, the statements DISPLAY, MESSAGE, and PUT will be used infrequently, and the UPDATE, SET, and PROMPT-FOR will never be used for screen input[1].
The Progress 4GL statements most used will be flow control (REPEAT, IF, RUN, PROCEDURE, etc), value manipulation (DEF VAR, DEF BUFFER, ASSIGN, etc), and Database manipulation (FIND, FOR EACH, SELECT, etc).
Some new functions are made available to handle input from the web. These have names such as GET-VALUE(), GET-FIELD(), and GET-COOKIE(). These functions will be explained later on the book.
The book does not explain HTML or Javascript, as there are other books that do that.
Almost all the activity that a user would be doing on the browser, whether filling in blanks for a form, or dragging and dropping entities with Netscape 4.0, will need to be done with javascript and HTML. Granted the programmer can get by on HTML only, but javascript is becoming a major influence to the thin-client paradigm.
Programmers who use Webspeed will probably also need to become familiar with MS Windows Operating Systems and UNIX Operating Systems. I will tell the reader right now I am a UNIX guy, but most people in the world are on MS Windows machines, so the browsers available on MS Windows that the application will support will need to be tested and that requires a familiarity with that operating system. In addition, it seems the best HTML editors are for the MS OS’s other than SGI’s Cosmo application. The hard-core transactions and web servers will likely be on a UNIX machine, as Windows NT has been showing some growing pains[2]. Hence the application programmer will need to be familiar with how UNIX works to gain the most benefit.
The book will cover the components of the Webspeed system. It will not explain in detail how to set up or administer webspeed, as that belongs to Progress. But I will include somethings so that I wished were in the manuals. An overview is included because Webspeed is a new programming paradigm for most Progress programmers.
Special thanks go to Mark Rigney and Mike Emmons for reviewing the manuscript for a sanity check.
About the author:
Scott Auge works for Auge, Emmons, & Ziola, Inc. He lives in Flint, Michigan, but is usually in some part of the country working on a contract for service and manufacturing oriented information systems to increase strategic and competitive standing for companies. It is best to reach him via sauge@aezinc.com .
Why use Webspeed?
Webspeed is more efficient in terms of computer resources. A browser program often requires much fewer resources in terms of memory and CPU speed than an executable client application. This can give hardware a longer life time provided the browser is the only application being handled on the machine.
Since the webspeed agents are actually progress clients, they can be better utilized than shared memory clients and networked clients on the same machine. Since multiple users can ask the client to do something, the memory and cpu space used by the client is better utilized. No more sucking up memory while a logged in user is drinking coffee doing nothing on the machine. As soon as a client is finished responding to a user’s browser, it can be asked by another user to do something – far more efficient regarding licenses and machine utilization[3].
Having the source code centralized on the transaction server machines means there is only one or two places that need source code modifications and updates. For user bases of 100’s and 1000’s, this can reduce program updates drastically!
Webspeed can be used on Progress, Oracle, Sybase, as well as Informix databases. This allows the webspeed application to interface with many legacy systems with a new WWW interface. The 4GL can be used in place of SQL to increase programmer productivity and to simplify the programming language used (though there will be times when SQL will still remain a requirement.) Since Webspeed is a transaction server linked to a web interface, web applications can be designed that transparently use the legacy data in existing DBs as well as create new data in the existing DBs without the user’s even being aware of it. With this, web applications may be able to overtake the functionallity of multiple applications into one unified interface accessable from a centralized location. In short, a web browser could be started up and procede to manipulate the data in multiple databases of multiple systems within the company all from one point in the user’s mind – no more click this icon on the desktop to reach order entry and that icon on the MS Office toolbar to reach the manufacturing system. One can even have one point of login – ya in, ya in. All systems can become one with the web interface, and yet users can still be delineated based on security from reaching different sections of the company.
Webspeed uses HTML and Javascript to handle user activities and 4GL to handle database transactions. Using HTML one can design a more interesting screen for the user to work with. In addition, HTML can transparently transfer the user from one machine to another machine without needing to start another program interface or “window” – though one still has the ability to do so if desired. HTML can be quickly thrown together by the programmers for prototyping to the users. HTML is a powerful means of describing screens.
Javascript will allow the programmers to have actions take place on the client machine. Though not as powerful as a data manipulation language, it can be used to turn fields on and off in the screen as data is entered into fields that effect the user’s ability to populate other fields in the same screen. Also it can be used to verify that a field in the screen has actually been populated when it needs to be populated. Computation can happen on the screen also as the user interacts with the browser before the browser interacts with the webserver.
One bad point on webspeed is that it is network intensive. If the network is overloaded or badly configured (routing or has 1 or more choke points) then the users may see a delayed response from the machine.
in a Webspeed Application
Introduction:
Below is a diagram of the components in a Webspeed application. This is simplified, and will be exponded on later in terms important to a programmer.
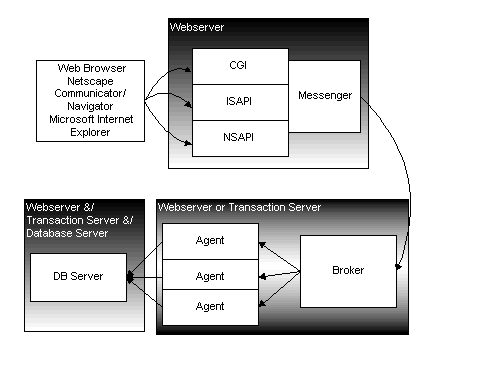
A description of the workings:
The user of the webspeed application uses a program known as a WWW Browser, or a WWW client. There are three main clients in use today: Netscape Navigator, Microsoft Internet Explorer and NCSA Mosaic. The browser is a thin-net client that performs rendering of HTML[4] into a human readable interface. The browser also provides rudimentary IO such as movement of the cursor, mouse clicking, and text entry. The Netscape and Microsoft browsers also understand two scripting languages called Javascript and VBScript.
The browser makes contact with the webserver. A webserver is a third party program (usually Netscape’s Enterprise WebServer, Microsoft’s IIS, or the internet’s Apache server.) It is a program that handles client requests for web pages.
In order for a Webspeed to function, the webserver will need a gateway feature. A gateway feature allows the webserver to execute programs that can create web pages on the fly. This is how data can be entered into a web page, or content relevent to the users interest can be made programmatically.
Most webservers handle the CGI gateway, but the Netscape servers can have special coding made available to the server thru the NSAPI as can the Microsoft servers can have special coding made available to the server thru ISAPI. It is thru this gateway a Progress component called a messenger is added to the web server to begin the ability of the web server to execute Progress programs (which of course can access the Progress DB, or any of the other major DB vendors[5] Progress supports.)
The messenger contacts a process called a broker (also a Progress component) who determines an available agent process (a Progress supplied component), and passes control to that agent.
The agent then executes a Progress .r file, allowing it to interact with the database, and generate the HTML that will be returned to the web browser thru the webserver. One can think of the agent as the progress client in the usual Progress paradigm, as in fact, it performs the same function as the client in terms of executing code and preparing output for the browser to use to render the screen.
Since the agents usually are using a different shared memory version than the database servers, a network connection inside the machine must be established. If the agents are to be communicating with a database on another machine, a network based connection will need to be made anyhow.
In order for the agents to execute any code that uses a database, they must talk to a database server process or a data server process (both supplied by Progress).
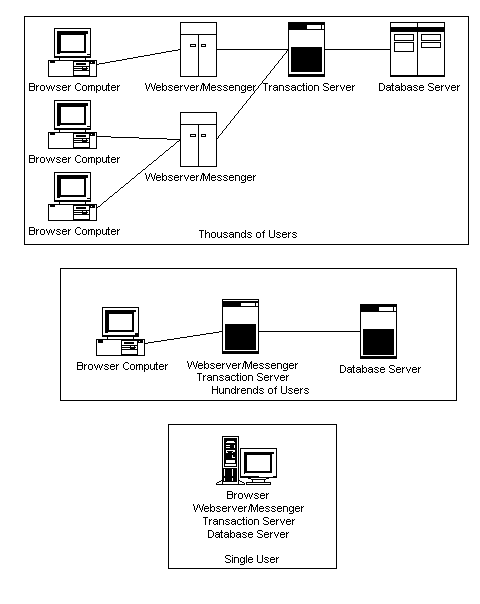
Quite often the processes are spread across multiple machines. This way inexpensive computing hardware can be used instead of one huge honkin machine. In general, the browser will execute on the users computer, though if the users machine is an X terminal, the browser may be executing on a different computer and the GUI interface is being sent to the X terminal. The webserver and the messenger processes must always be executing on the same machine. The broker and the agents also usually are executing on the same machine, though it may be different from all the other machines. The database server process can also be executing on it’s own machine. So in a very large system, there could be four or more computers involved. In a smaller system, there could be two computers involved. In general, the system will have three computers involved: Browser computer, web server/messenger/broker/agent computer and a database computer. Larger systems can handle more users by spreading the processes needed to handle the users across more hardware.
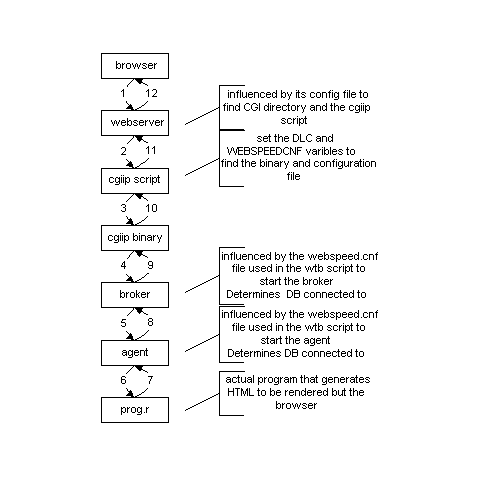
Following the activities thru the system (UNIX):
First the browser uses a DNS server to determine the IP address of the machine named in the URL to be contacted[6].
Next the port specified[7] is tickled and the webserver answers the connection. The webserver then parses the URL sent to it and decides if it needs to run a program in the CGI directory[8] or if it can serve a page directly from a document directory[9].
Should the URL point to a document directory, the server returns the static HTML stored in the file specified.
The more interesting part is when the URL means to execute a program on the web server and that program is the messenger component of the Webspeed Transaction server.
That program in the CGI world is a script that sets the environmental varibles WEBSPEEDCNF and DLC that is used by $DLC/cgiip to begin communication with the transaction server portion.
A connection is made between the messenger and an agent handling the broker service that the messenger is asking to be handled. The agent is passed the program name to run[10] and performs the run according to the default directory or PROPATH it is was instructed to use in startup.
The agent then usually interacts with the database thru a network connection.
Below is a diagram showing the steps involved diagramatically without the DNS entries as the /etc/hosts or \windows\hosts files could be used on an intranet based application.
How to set up a messenger on a different machine than the transaction server (UNIX):
To help seperate the pain of computation, the implementor may want to use a machine to act as the web server and another to handle database transactions. Seperating the processes to multiple machines can reduce the size of the machines needed, and the implementor may even be able to use machines in existing inventory. The more powerful machine should be made the transaction server, and the less powerful machine can be made the web server.
1. The messenger portion of the Webspeed transaction server will need to be installed on the webserver, and the webserver will need to be made aware of the messenger thru the webserver's configuration file.
2. Set up the webserver to have a scripts directory
3. Place the wbsp_cgi.sh file into this directory
4. Rename it to something easier to remember in terms of the application.
5. Edit this file, you will want to hardcode the DLC environmental varible environmental varible so unneeded processing is required to find the webspeed.cnf file that will handle this application and messager. (There is a small do loop in the script that searchs a set of directories, this means disk accesses for the messenger on every hit which can slow things down a tad bit – if your a purist.)
6. If the webspeed.cnf file is not in the DLC directory, you will want to hardcode the WEBSPEEDCNF environmental varible to point to the correct webspeed.cnf file[11].
7. Edit the webspeed.cnf file pointed to by the environmental varible WEBSPEEDCNF in the messenger script file in the webserver's CGI directory. The entries of most interest will be:
PortNum 2001 # Service TCP/IP listening port
Location 100 # 200=Local, 100=Remote
AgentMinPort 2002 # Minimum port number for Agents
AgentMaxPort 2202 # Maximum port number for Agents
HostName remotemachine # Name of local or remote hostname
A different webspeed.cnf file, pointed to be the wtb script to start up the broker and agents will have the same information, except for the Location parameter, which will be 200 to state the webspeed.cnf file refers to a local broker and agent process(s).
PortNum 2001 # Service TCP/IP listening port
Location 200 # 200=Local, 100=Remote
AgentMinPort 2002 # Minimum port number for Agents
AgentMaxPort 2202 # Maximum port number for Agents
HostName remotemachine # Name of local or remote hostname
The port numbers for the webspeed broker and agents should be the same for the given application environment.
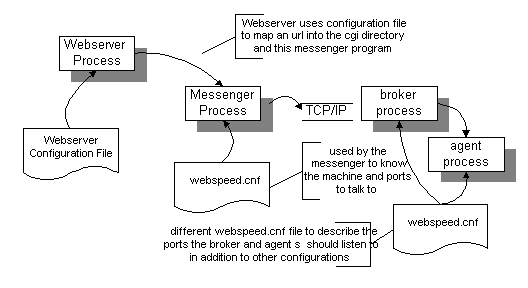
Those seven steps pretty much explain how to get two machines talking to each other in regards to messenger-broker-agent communications.
How to set up the transaction server on a machine different from the database server machine:
The following describes the entries and processes related to getting agents and brokers on one machine to talk to a database server on another machine.
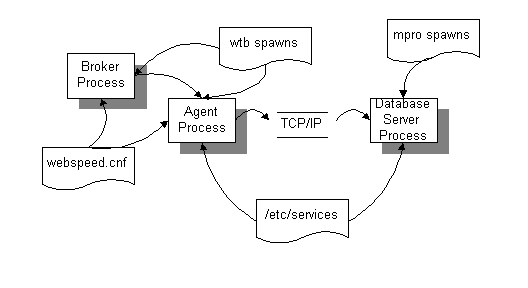
Files and processes involved in getting agents-broker-database server communications....
The broker and agent processes are spawned from the wtb script found in the webspeed DLC/bin directory. These scripts make reference to a webspeed.cnf file that will include the connection parameters for connection to the remote database.
DefaultDirectory /appl/rel1 # Broker & Agents working directory
AgentParams -p web/objects/web-disp.p -cpstream iso8859-1 -db d1prod -ld dispatch -H aupaix1.fld.rolm.com -S d1prodpost -N TCP -db rolmdbd1 -ld rolmdbd1 -H aupaix1.fld.rolm.com -S rolmdbd1post -N TCP -db websecurity -ld websecurity -H scraix11 -S websec –N TCP -T /tmp
As can be seen, the connection parameters are based on -db, -ld, -H, -S, and -N parameters normal to Progress clients. These parameters mean the following:
-db Physical name of the database
-ld Logical name of the database
-H Host name with the database to be connected to
-S Service used by the network connection - defined in /etc/services
-N Type of network connection (TCP is usual value)
A .pf file can also be used instead of specifying the database connection parameters.
How to set up multiple environments on the same machine:
This is how I prefer to do things, but there is more information within the Webspeed Administration manual. I find the following steps allow you to construct URLS that are a bit more easier to remember than including the WSbroker=blah in the text.
1. You will want a cgiip script in the cgi directory for each environment. Give each script a name that describes the environment. Within the script, there will be a call to $DLC/cgiip –i [brokername]. Yep, you guessed it, put the broker name after the –i in the script.
In the webspeed.cnf file used:
2. You will want to set up multiple broker settings, give each broker a name that describes the environment. This can be helpful for remembering what application the broker is for, and whether the application environment is develop, test, or production. Examples could be cdrdev, cdrtst and cdrprod.
3. Set up different ports for each set of brokers, agents of different brokers can share the same ports. You definately do not want to mix up the ports for the various brokers in the system.
4. Set up the parameters in the webspeed.cnf file as mentioned above or from the explainations in the Progress Webspeed Administration book.
Basic Components in a Webspeed Development Environment
Introduction:
Developing web based applications requires many components and third party tools. Below is a diagram attempting to describe the relationships between the major source files and the tools. Some of the source files are not needed depending on what method of development used.
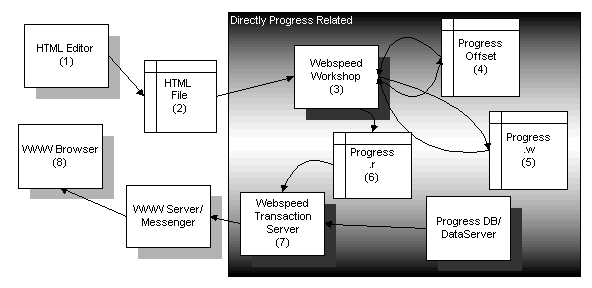 Webspeed
Development Environment
Webspeed
Development EnvironmentThe programmer or screen designer will layout the screen in an HTML editor(1). It is always best to have the screen laid out before adding the javascripting, 4GL, or Java added.
Then an HTML file(2) is created from the editor.
The Progress programmer then uses Progress’ Workshop(3) tool to prepare a webobject that will prepare the page with Progress’ 4GL language.
The next step depends on if the programmer will use the E4GL method of development or the HTML-Mapped method of development. The HTML-Mapping method requires an offset file(4) and a .w file(5). The E4GL can have a .w file(5) if needed for deployment on another machine, but does not need the offset file(4). The Workshop product can automatically create these files – but note that some of them will merely be skeletal renderings of the file (basically what it takes to get data in and out of the screen – but no processing.
The Workshop tool is then used to create a Progress .r file(6).
The Progress Transaction Server(7) tool is used to execute the .r file against a given database (should the code state so under the conditions) and then to return the output of the .r file to the browser(8).
The First Step: Developing the Web Page
Introduction:
When coding is ready to begin on a Webspeed application, the fastest way to prepare the webpage is thru the use of an HTML editor. There are many editors available for both UNIX and MS OS’s. The best type of tool to use is one that allows drag and drop of various web page entities, such as buttons, fields, and images.
Developing the web pages also allows the users to actual see a mock up of the application as it is being developed. The users should be made aware that at times the application will need much work to be done under the hood even though it may look to be almost finished because it is appearing in a browser. A good explaination might be that it is drawn out like on electronic paper instead of on solid paper, and has as much functionallity as a screen drawn on paper.
Some tools to use in the MS Environment:
Hotmetal Pro has an editor that I like. Just about the only thing I do not like about it is being unable to re-size images by dragging an achor point. If you wish the browser to show a certain size, ya will need to work the numbers your self.
Another potential tool to use is MS Front Page. This tool is good for developing the intial page, but be aware that it does add some additional comments and tags to communicate with other Microsoft tools. I fear that this tool is becoming proprietary to Microsoft systems and is slowly evolving away from being useful in other environments.
A third canidate is the HTML editor available from Netscape called Composer. This tool is a bit weak in terms of capability. It is good for general layout, but for more complex tags, such as forms and the like, it requires the user to enter the actual HTML.
Finally a text editor can be used for people who are hard core HTML authors and have the skills to create HTML pages on the fly without help from a tool.
Some tools in the UNIX Environment:
Often the UNIX vendor will have an HTML editor available for it’s machine, or will be aware of an editor(s) that will function on the machine.
SGI has the Cosmo suite, that allows the user to develop web pages. This is a very nice editor with drag and drop and is user friendly.
Netscape provides it’s Composer tool in many UNIX environments, including Sun, Linux, UNIXWare, and Open Desktop, HP-UX among others….
Usually HTML editors are available at various internet sites, as one editor on one version of UNIX is made available on other versions as well. Linux has many HTML editors available for it for those who prefer a UNIX work station environment.
Some ways to documenting and analyzing web pages:
As you can consider, developing a web based system will require some changes in what information you want to document and how to document it. Below is an example of some of the notation[12] that could be used to express your ideas about how screens are interconnected and what data is passed between them.
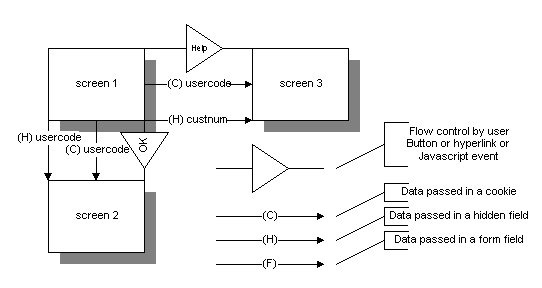
There are three main types of symbols: screens, data arrows, and flow control arrows. Screens would represent the screens that you wish to have a web object generate. It could be the same web object generating different screens, could be a single web object generating all the screens, though I would think this would be a nightmare.
The screens are named or denoted in some way for reference. They are represented by boxes with a shadow underneath.
Flow between screens by activities of the user is denoted with a special arrow. This helps identify the activities the user could do to move from screen to screen. Examples would be a button with an onclick event opening a window and page, or more simply a submit button. It could be a hyperlink that would be available to the user, or some types of events that could be programmed in the client’s (read that – browser’s) scripting language.
Data is passed between the screens, and this tends to be important to us programmers who need to understand what is coming in and what is coming out. Data can be in different forms when it comes out of a web page, the two most popular being in a cookie and a form field of somekind. In the future it may even be coming from a Java applet.
Since the data is coming in different entities and HTTP methods, that data will have differing properties. For example, it is much easier to reload()[13] a page activated by a GET than a POST. The data could be encapsulated in a form field, or sent via a cookie. The use of a symbol to denote the encapsulation method of the data can help sort out how the data is being transferred around in the system of pages. Some denotations I use are ( C ) for cookie, (H) for a hidden field, and a visible form field with (F). Next to the symbol for how the data is being transferred, I place the name referencing the data in the HTML.
Documenting the Progress 4GL can be a little tricky also, but will probably be more familiar to the users. A separate diagram can be set up to document calls into various routines with the 4GL:
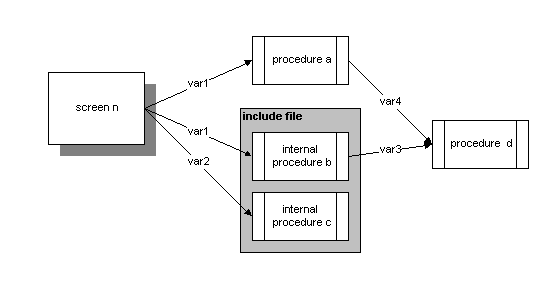
This diagram shows a screen with calls into multiple modules of Progress 4GL. Two modules are Progress internal procedures contained within an include file that are given certain arguments to work with. Two modules are external procedures stored in their respective files who are also given values to be worked with.
Between these two diagrams, a lot of information can be provided about the interaction of pages and of Progress modules that are generating the pages. It may be difficult to separate the two at first, and in a way they are related. But I usually try to differentiate data passed in Progress syntax at one level, and data passed in HTTP syntax at another level.
Integrating these diagrams into programming documentation seperated out by feature or function can help explain what is happening in the system, and potentially what is can be optimized. In addition, if customizations are occuring in the system, whether in the form of maintenance or in feature modification, the consequence of changes can be better determined.
A sample outline for a specification document is given below:
Business Scenerio
- Describe what the program or feature is attempting to do within the organization
- Who the players are
- What process the person using the application will be in
- Where they will be getting data to place into the screen
- Who they will be giving their data to when they are finished manipulating it
User Interaction
- Give a screen layout
- If buttons on the screen, then say what they are going to do
- Screen field validations
System Interaction
- The not so obvious stuff such as database triggers involved
- Program Names that will be created or re-used
- What is going to happen on all the tables involved within the system
- What screen field lands in what tables in what conditions
- What screens are interacted with and data passed between
Database Tables
- Which ones are used
- Which ones are created
- Fields, Indexes, etc.
Note that you documenting system should be able to handle keyword searching or somekind of indexing for easy referening.
Could be MS WORD with keywords for the document. Then set up keywords for questions you will want to ask:
- Tables used by other programs (to make sure something else doesn't get broken)
- Other Validations for the data
- Programs used (for feature interaction)
General New Features in
Progress 4GL for Webspeed
Introduction:
As can probably be guessed now, the usual 4GL statements associated with interacting with the user are rarely relevent[14]. In the web paradigm, a browser takes the place of the GUI front end for an application. The following chapter explains the general programming functions the programmer will need to be aware of to create web objects executing near or at the back-end of the process chain to implement a webspeed application.
If the HTML is used to gain and store values for values, how do I get them from the HTML into the 4GL?
We know that HTML provides the information to the browser on how to render the pages: where to put words, diagrams, and input fields. Some examples of instructions to a browser are:
<input type=”button” name=”userbutton” value=”OK”>
will create a button on the page, label it with OK and name the button (for internal reference from javascript and the 4GL as we will see in a bit) as userbutton. Note the entire instruction in HTML, no 4GL has been used yet. In essence, we have created an HTML varible, and named it userbutton. We have instructed the browser to render values of the varible on a button on the web page.
Another more interesting HTML “widget” would be the text field. An example coding for a text field is given below:
<input type=”text” name=”firstname” value=”” width=”30”>
This would create a 30 character wide (but usually able to hold more than thirty characters – think of it as a fill-in widget in the 4GL) entry space for the user to type some string of characters into. Here we have created a varible named firstname and issued instructions to the browser to render it as a textual field.
So then, how do we get the value from the HTML varibles into the 4GL varibles? By the use of a special function made available in the Workshop product. It is called:
GET-VALUE()
This function will return a string representing the entry performed by the user on a form on the browser. It’s argument is the HTML varible name.
An example would be:
<!DOCTYPE HTML PUBLIC "-//SoftQuad//DTD HoTMetaL PRO 4.0::19971010::extensions to HTML 4.0//EN"
"hmpro4.dtd">
<HTML>
<HEAD>
<TITLE></TITLE>
</HEAD>
<BODY>
<P>First Name: </P>
<FORM><INPUT TYPE="text" NAME="firstname" WIDTH="20">
<INPUT TYPE="submit" VALUE=" OK "></FORM>
</BODY>
</HTML>
which would be the HTML used to render a screen appearing as:
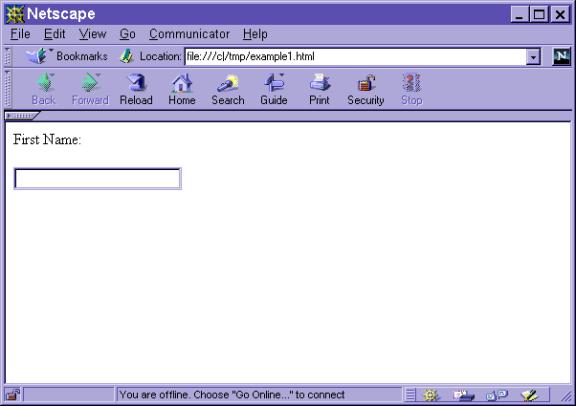 As can be seen, there is one text box on the screen that the
user can use to input a name and one button to “submit” the screen.
As can be seen, there is one text box on the screen that the
user can use to input a name and one button to “submit” the screen.
To receive the data from the browser (which is controlling the user interaction with the program, NOT your 4GL as in previous progress programming), one uses the following:
DEF VAR FirstName AS CHARACTER NO-UNDO.
ASSIGN FirstName = GET-VALUE(“firstname”).
These two 4GL statements will define a varible to move the contents of the HTML varible firstname into the 4GL varible FirstName. How to mix the 4GL and the HTML together depends on which development method is used: HTML-Mapping, or E4GL scripting.
There are additional functions available to nab the values of types of widgets in an HTML page, see your Webspeed Programmer’s guide for more information on this.
In addition to what is seen on the screen, there is a special means of storing data on the browser called a cookie. A cookie can be stored on a browser during a given unit of time, or as long as the browser is open and then destroyed. Cookies are an excellent means of storing information about who is logged on to the application for application security. More on that follows.
The means to get a cookie set on the browser is by using the SET-COOKIE() function[15].
To read a cookie one uses the GET-COOKIE() function.
Note that all values passed between the HTML and the 4GL are in the data type character. If integers are passed in from the HTML, they will come into the Progress code as CHARACTER. Same for dates, logicals, and other data types.
An example of how to handle potential trouble is via:
DEF VAR a AS INTEGER NO-UNDO.
{error.i}
ASSIGN a = INTEGER (GET-VALUE (“thenumber”)) NO-ERROR.
IF SESSION:ERROR THEN RUN handletheerror({&BADINTEGER}).
Developing with the E4GL method
Introduction:
The E4GL method is the fastest method to learn if the programmer is already familiar with web based programming. It involves using special HTML markers to note where the 4GL code is. It is a convenient way to combine HTML, Javascript, VBScript, and 4GL code together into one source file, that way all the peices to the puzzle are made available immediately to the programmer.
The term E4GL stands for Embedded 4th Generation Language.
About the Method:
E4GL is directly embedded in a program that appears more like a static HTML page, than a program. But as we will see later, the page is manipulated by a tool called Workshop available from Progress to convert the page into a progress program.
Embedding is done via two ways, one is a special comment tag as follows:
<!—WSS
Progress 4GL code
à
and the other tag more familiar to HTML authors and Javascript/VBScript programmers:
<script language=”speedscript”>
Progress 4GL code
</script>
In addition, the accent grave or back tic (`) as it is known is used in special cases within the HTML or Javascript making up a webpage. This tic is used to output values of a varible, or any 4GL expression that returns a value. For example, the following code outputs a textbox with a default value derived from the varible textdefault:
… Some other HTML
<!—WSS
DEF VAR textdefault AS CHARACTER NO-UNDO.
à
<form>
<input type=”text” name=”t1” value=”`textdefault`”>
</form>
One can see in the browser a text box whose value is set to the value of textdefault in the Progress 4GL language.
Now the question is probably coming up on how do we compile this HTML file into a Progress executable. The WebSpeed Workshop will be required to go into this next step, unless a third party converter is used[16].
What workshop does in short is create a STREAM WebStream that is for output. It then puts PUT STREAM WebStream[17] in front of all the HTML statements quoting the statements with single quotes in the HTML file. If this converter encounters the special tags, it stops putting the PUT STREAM WebStream statement in front of the lines and leaves them alone creating a pure Progress source file.
So the line:
<input type=”text” name=”t1” value=”`textdefault`”>
will be turned by the converter into:
&{OUT} ‘<input type=”text” name=”t1” value=”’ /** Tag ` **/ textdefault /** Tag ` **/ ‘”>’.
Which when the Preprocessor is finished with it comes out effectively as:
PUT STREAM WebStream ‘<input type=”text” name=”t1” value=”’ textdefault ‘”>’.
So as one can see, the WebSpeed Workshop, when creating .w’s or .r’s from HTML pages creates PUT statements that will output HTML (and javascript or VBScript) to stdout (in UNIX terms) that is passed directly by all the components between the agent and the browser.
Those parts delimited by the special tags are left alone, because they are already Progress 4GL statements. Placement of the Progress 4GL statements in the E4GL style is very important in the HTML file. Because the execution of the program goes top down with it’s processing the programmer will always want their HTML PUT statements to be at the end. If the programmer has their HTML at the top, and processing of varibles and the like at the bottom, the HTML will not have the correct values because it was output before the values where computed.
In general, the following outline is best for E4GL programs:
1. Varible Definitions
2. Populate varibles
3. Perform record processing
4. HTML code
5. Internal Procedures
Below is a simple program that will create a record using the outline as specified above:
<!DOCTYPE HTML PUBLIC "-//SoftQuad//DTD HoTMetaL PRO 4.0::19971010::extensions to HTML 4.0//EN"
"hmpro4.dtd">
<!--WSS
DEF VAR CustomerName AS CHARACTER NO-UNDO.
DEF VAR CustomerNumber AS INTEGER NO-UNDO.
ASSIGN CustomerName = GET-VALUE ("custname")
CustomerNumber = IF CustomerName <> "" THEN NEXT-VALUE (CustomerNumber)
ELSE 0.
IF CustomerName <> "" THEN DO:
CREATE Customer.
ASSIGN
Customer.Name = CustomerName
Customer.Number = CustomerNumber.
END. /* CustomerName populated */
-->
<html>
<body>
<form method="POST">
Customer Name: <input type="text" name="custname" value="`CustomerName`"> <br>
Customer Num : <input type="text" name="custnum" value="`CustomerNumber`"> <br>
<center>
<input type="submit" name="Submit" value="OK">
</center>
</form>
</body>
</html>
Documenting it under the above mentioned diagrammic method would appear as:
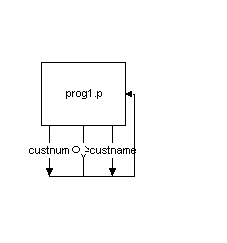
And viewing the screen would appear as:
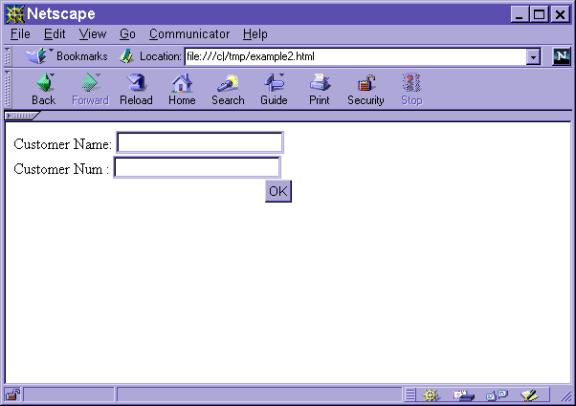
In general, the programmer will always want the HTML to be the last thing in the main program procedure. The entirety of the HTML can be encapsulated into an internal procedure that is called from the program. This can allow better control as to when the HTML is going to be output. In fact, the same program could output an entirely different page based on processing by calling one internal procedure with the HTML in it versus another internal procedure with HTML in it.
So, how does this program work?
Here, an understanding of how the Browser and the Web Server interact comes into play. Initally the browser will request thru an URL that this program be executed. On this initial connection, the REQUEST_METHOD is GET.
1. The program will receive no input, causing the GET-VALUE() functions to return nothing.
2. Some processing shows up where it is determined if any input was sent or not and the creation of a record is based upon this decision.
3. After that, the results are output to the browser, which is pretty much the empty form.
4. The user will enter some information and press the OK button causing a submit to occur using the POST method. Since the ACTION in the form is not defined, the browser will call for the same URL as used in the GET and pass information along to the program.
5. This time, the GET-VALUE()s in the program will receive some data firing the IF and a record will be created, where the output will refect that because of the existance of a customer number.
It must be remembered that the program is executed twice! Once when it is first entered and second when the OK button is pressed. Based on the values available to the program from the GET-VALUE() is what really drives the activity of the program. It is stateless and thereby started up and shut down with each request from the browser. One can think of it as starting up a client session and getting some output on the screen. Then kill the connection. At this point the browser takes over allowing editing of the fields. The user presses OK, and the browser recognizing the submit will again establish a client session to the database and execute a program[18].
So a continous connection is not in the plan for this particular program.
Coding for HTML elements:
Text Box
Text boxes are among the simplist to handle. If the user wishes to default a value thru Progress 4GL, then the programmer would use the accent graves to delimit the varible in 4GL from the HTML.
<input type=”text” name=”thename” value=”thevalue” width=”20”>
Button
Buttons dont really do anything unless they are a type of submit or reset. Else, to get the button to be functional, javascript or vbscript will need to be used.
<input type=”button” name=”thename” value=”thevalue”>
Submit
These buttons do the brunt of the work when activities on the server side need to be performed. This can be the creation, modification, and deletion of records in the database, or for changing “state” information used within the program.
<input type=”submit” name=”thename” value=”thevalue” >
Radio
Radio widgets are good for “this or this or this but only one of em buddy” situations. Only one out of a group can be checked at a time.
<INPUT TYPE="RADIO" NAME="Radio1" VALUE="Value1" CHECKED="CHECKED">
<INPUT TYPE="RADIO" NAME="Radio1" VALUE="Value2">
By having the same name, the buttons become dependent on each other. This way when the user checks on one, the other will become unchecked. By using the CHECKED parameter within the tag, the programmer can specify a default value. To determine which widget was checked, do a GET-VALUE(“Radio1”). A return of Value1 will mean that the first item was chosen by the user, a return of Value2 means the user overrode the default from the first radio button the the second radio button.
Checkbox
Check boxes are like radio buttons, but have a different look about them. Mostly used in those areas where interdependence between check boxes are not required.
<input type=”checkbox” name=”thename” value=”thevalue”>
Text Area
The textarea widget allows the programmer the ability to give the user someplace that acts as a small editor.
<input type=”text” name=”thename” width=”20”>defaulted text</textarea>
The above were very small descriptions on the main items a programmer would be using to construct a web application. More information about other input mechinisms and additional properties of the ones above can be referenced from any HTML reference book.
Keeping business logic out of the HTML:
This is becoming a very important issue for companies, as we are seeing tools for user interfaces propagate in the market – there are many many more choices.
In general, the programmers should make an API for nearly every business rule in the company. Really there should be no CREATEs, DELETEs, or database record ASSIGNs in the E4GL portion of the code. The user interface portion of the application should use RUN’s to perform the work of business logic. Business logic APIs will accept only arguments and will not provide any output or input to the screen (this does not mean it cannot provide a list of ROW Ids or Record Ids for the interface to work with however!)
For example, there could be an order entry screen, and on that screen there are entry lines and a few buttons.
We would name all the buttons the same way, and they would all be submit buttons (we need to use submit buttons to interact with the web object on the other side of the webserver)
The following code allows the programmer to know what button was pressed to submit the page into the webserver:
DEF VAR ButtonValue AS CHARACTER NO-UNDO.
ASSIGN ButtonValue = GET-VALUE (“SubmitButton”).
There will be additional code to read in the various values from the form using the GET-VALUE() function:
ASSIGN CustomerNumber = GET-VALUE(“customernumber”)
Item1 = GET-VALUE (“item1”).
A call would be made into the API for the button called Create Order:
/* ID Button Pressed – the event dispatcher*/
CASE ButtonValue:
WHEN “Create” THEN RUN ipButtonCreate.
WHEN “Cancel” THEN RUN ipButtonCancel.
END. /* CASE ButtonValue */
This allows the programmer to become somewhat event oriented, on the event the Create button was pressed, then the ipButtonCreate[19] program will handle that activity of the user. A general feeling of what happens could be done like this:
/* An event handler */
PROCEDURE ipCreateButton:
ASSIGN var1 = GET-VALUE (“var1”)
var2 = GET-VALUE (“var2”).
RUN CreateOrder (INPUT var1, INPUT var2, OUTPUT result).
END. /* PROCEDURE ipCreateButton */
Inside the CreateOrder program would be all the business rules associated with creating an order. If an error occurred because a business rule was broken, then coding would be used to explain to the user what went wrong. For example, there may be a credit hold on the customer, or there may not be inventory available for that product. A result would be passed back from the CreateOrder program and that result would be examined by the event handling code to determine what message, if any, needs to be displayed to the customer.
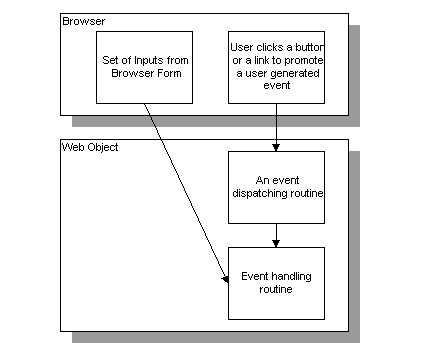
Coding Architecture for Seperating Business Logic from UI in Webspeed E4GL applications
Note, that GET-VALUE must be used in a program with {e4gl.i} included at the top, else it will not be defined for use. So in these APIs which are .p files, the programmer will not be able to use GET-VALUE because it will not be defined in that program. The recommended way of getting information on an event spawned execution, is to perform this in an internal procedure. The internal procedure would act as the wrapper between the interface and the API.
Author's note: I have stopped developing this chapter of the book because I do not believe in the HTML-Mapped method of development in Webspeed. It is difficult to use, creates larger .r files than the E4GL method, requires the distribution of three files (.r, .off, html) instead of one .r, is slower due to parsing of .html and .off files, more fragile to html changes, and generally requires more development time than the E4GL method of coding.
Introduction:
This second method of development will probably be more familiar to Progress programmers as there is little to no work done on the HTML file.
Using this method requires heavy use of the Workshop product as it creates a lot of code for the programmer getting values into and out of the HTML form.
One of the bad points of this method is that it requires parsing the HTML file nearly everytime the program associated with it is run. In addition, coding a program in E4GL took significantly fewer lines of code to write than in the HTML-Mapped method, resulting in a smaller and assumingly faster .r file. In fact, one test with the exact same functionallity showed that the E4GL program compiled to a 17KB .r while the HTML-Mapped program compiled to a 38KB .r file.
In addition, the HTML and .off files need to be sent along with the .w files. While the .w files can be encrypted, the html and the .off files cannot be encrypted and can be manipulated by the user. Adding a field to the HTML file will cause an error and requires a new offset file and a re-compile of the .w to work properly.
With E4GL, only the .w files need to be sent in encrypted form and compiled to be useable on a customers site.
About the method:
Use a HTML Editor to create the HTML Page.
Use the Workshop to create an offset file.
Use the Workshop to map the fields from the form, to varibles or fields in the CGI Wrapper.
Save the CGI Wrapper file (it will be a .w)
Edit the CGI Wrapper with the business logic.
Components of interest in an HTML-Mapped .w file:
WEB-FILE
This is a preprocessor definition that identifies the HTML file to map to and to use to format the output of the wrapper program.
ENABLED-OBJECTS
This preprocessor definiton identifies fields that will be editable in the browser.
DISPLAYED-OBJECTS
This preprocessor identifies the fields in the web frame that will be displayed, ie, used to replace the fields on the HTML form shown in the browser.
Local Varible Definitions[20]
For fields that do not directly effect a database record, local varible definitions are created. These are the varibles as defined in the HTML-Mapping phase in the Workshop.
Web-Frame Definition
This will act as the screen buffer for those familiar with such an entity. There really is not a screen buffer in the Webspeed world, as the program really is not interacting with the screen. But it is a convenience for those familiar with using a screen buffer for various activities.
RUN web/support/rdoffr.p
This pretty much makes sure the fields in the offset file created via the Workshop match what is in the HTML file.
RUN htm-associate IN THIS PROCEDURE ()
This procedure associates the form fields name, the varible or buffer field, and a handle into the screen buffer defined in the Web-Frame. This where all the values are glued together.
PROCEDURE output-header
This is where the user will set cookies or other information before the browser starts to receive HTML.
PROCEDURE process-web-request
This is the procedure that defines the heart of the business logic in the application. There are two main parts, one part for handling a GET and one part for handling a POST. A GET will usually be the first time the screen is brought up by the user, and so it is useful to place default values into fields that the user may be editing, as well as prepare hidden fields that the user may be using to keep state information.
For a POST REQUEST_METHOD:
RUN dispatch in THIS-PROCEDURE (‘input-fields’:U).
This function will take fields and values from the URL and set them into the Web-Frame as defined in the htm-associate procedure.
RUN dispatch in THIS-PROCEDURE (‘assign-fields’:U).
For those fields that have been manipulated in the form buffer, a movement from the buffer into the database occurs.
RUN dispatch in THIS-PROCEDURE (‘display-fields’:U).
This allows the user to manipulate the form buffer again for values that should be displayed.
RUN dispatch in THIS-PROCEDURE (‘enable-fields’:U).
Running this procedure identifies the fields that should be enabled for user interaction. If you wish some fields to become inactive, Ie, display, but not allow the user to change the value, the programmer should enter a DISABLE statement after a call to this program.
RUN dispatch in THIS-PROCEDURE (‘output-fields’:U).
This is where the screen is rendered to the browser with the values from the form buffer entered into the fields and the fields made interactive or not interactive.
For a GET REQUEST_METHOD:
RUN dispatch in THIS-PROCEDURE (‘display-fields’:U).
See display-fields in the POST REQUEST_METHOD.
RUN dispatch in THIS-PROCEDURE (‘enable-fields’:U).
See enable-fields in the POST REQUEST-METHOD.
RUN dispatch in THIS-PROCEDURE (‘output-fields’:U).
See output-fields in the POST REQUEST-METHOD.
Deploying your webspeed application:
Tips and Tricks in Webspeed
Introduction:
A lot of the tricks achieved are really in the HTML and the Javascript/VBScript used in the application. The 4GL really just manipulates the database in the system.
How to get agents to handle different databases:
You want the webspeed environment to handle different databases. This is done by having a different brokering service.
Looking inside the webspeed configuration file, one
Since I usually use CGI as the interface into the web server, to create access into the given database is by running a different cgiip. Here is what I do, I have two databases: one handles customer orders, and one handles customers support questions.
Copy the wspd_cgi.sh to orders and to support. Inside orders, I would set cgiip –i WSbroker where Wsbroker handles connections to the orders database. Inside support I would set cgiip –I Wsbroker2 where Wsbroker2 handles connections to the support database.
Hence the URL the user would see would read something like:
http://machinename/online/orders/login.html
for the orders submission and lookup, and
http://machinename/online/support/login.html
for the support submissions the customer might have.
Both orders and support would reference the same webspeed.cnf file. Inside the webspeed.cnf file I would set up a set of Messenger/Broker ports for the WSbroker connections to the databases and another different set of Messenger/Broker ports for the WSbroker2 connections.
Starting up the support system would entail:
1) Starting the databases needed by the transaction server
2) Entering wtb –i WSbroker2
Starting up the order system would entail:
1) Starting the databases needed by the transaction server
2) Entering wtb –i WSbroker
To check the status of the systems would use the commands:
wtbman –q –i WSbroker
for the order system and
wtbman –q –i WSbroker2
for the support system.
To shutdown the transaction server for a given system would use the following commands:
wtbman –e –i WSbroker
for the order system and
wtbman –e –i WSbroker2
for the support system.
Laying out the files for webspeed system:
This is generally a UNIX centric layout for applications, but something like it can be done with MS OS’s.
/appl
This is usually the central trunk for the tree that will contain the components of an application. If multiple applications are involved in a system, then a further break down may be desired.
/appl/db
Keeping the database in a close place next the rest of the application in the system can be a much more clean and clear explanation of where to find data for an application. One may want to further subdivide the /appl/db tree into /appl/db/devlp for development versions of the database, /appl/db/prod for the production databases and /appl/db/qa for the qa database.
As can be expected, the implementor will probably want to keep the database on a separate drive than the source code. Most UNIX systems will allow you to mount a hard drive to a directory “in the middle” of the directories of another hard drive, thus looking like the directory is all togetther. This can help in contention and changing hard drives out to bigger drives without needing to reconfigure the scripts and such used to connect and interact with the database.
If you have logical volumns, which can make a couple of drives look like one, I won’t even go further as you should already have an idea of what I am talking about.
/appl/bin
Usually the startup and shutdown scripts are stored here for a given environment. You will need a startup and shutdown script for the db (if the db is on the same machine as the transaction server) as well as a startup and shutdown script for the transaction server portion of webspeed.
If you are managing multiple applications with Webspeed you will probably want separate scripts for each application. Then include those scripts in calls from a superscript if so desired. Be aware that the “super script” that does everything may freeze up because of some un expected event that may not relate to any of the other applications the script is suppose to handle. So keeping the scripts separate allows the administer to get other applications running in case one application causes trouble.
/appl/src
As you may guess, I usually keep the source for the application in this area. It could be encrypted or .r source.
/appl/static
Webspeed applications have a new component to them, and that is the use of icons and graphics within the application that can be directly served by the web server without any intervention of the Webspeed application. I generally make a rule in the webserver’s configuration to map the directory of an url into this directory[21].
Use relative URLs in your application:
Only use relative URLs in application unless one must hyperlink to another machine than what is being used. Using SCRIPT_PATH and other such available varibles may be tempting, but having the machine within a fire wall can cause trouble.
For example, the customer did not want the web server and the messengers to be outside the fire wall. To solve this problem, they used the fire wall software’s ability to translate IP addresses into another IP address to get access to the internal machine. In other words, the machine to the internet looked like machine1.a.com, but the machine thought it’s name was machine.b.com as the internal domain was different from the external connection domain. Of course, the varibles were giving the internal name of the machine, and not what it looked like outside of the firewall – thus the URLs supplied the machine were giving the wrong name and the internet users could not find that machine. Some tricks with DNS and aliasing managed to save time re-programming, but it still was a bit of a hocky way to do things.
Design the pages before entering E4GL coding:
I have found that designing a page up front with Front Page or Hot Metal Pro can help the customer to see what things are going to look like before programming needs to be done. These layouts can be provided to them with sample data in the layout allowing them to explain modifications that need to be done before actual programming begins.
Once programming has begin, you will likely not want to return to the HTML editor as most of them totally trash the formatting of your 4GL coding after you enter it into the file. So having the layout agreed upon before coding can save a lot of time, and explaination.
How to get agents to handle a PROPATH:
The agents may be asked to handle working two application, which are differentiated by the broker service they are providing. In this way, the agents can actually handle two different applications at the same time with different database connection (isnt that rocking!)
To make the agents aware of the different directories of source code can be achieved by two means.
One is to have the default working directory[22] for the set of agents started under one broker service to be set to an application directory, and the other broker service to have a different default working directory.
Another is to make a copy of the wtb command found in the bin directory of the DLC the transaction server was installed under. The wtb command is actually a script describing where to find the executables and webspeed configuration files for starting the transaction server under. By copying these files and adding a notation for PROPATH, all the agents started with that script will be aware of the PROPATH and use them like the client versions of Progress.[23]
Some examples can be:
To start the orders transaction server:
#!/sbin/ksh
# start orders transaction server
PROPATH=$PROPATH:/appl/orders/custom:/appl/orders/src
wtb –i OrderBrkr
and the script to start the agents for the support transaction could be:
#!/sbin/ksh
# start support transaction server
PROPATH=$PROPATH:/appl/support/custom:/appl/support/src
wtb –i SupportBrkr
Use surrogate keys:
Surrogate keys is a database architecture technique that can help reduce the number of record changes that occur when the value of a relational field is changed. In addition, it can help reduce table size in databases for a common relation thru-out the database table architecture by the elimination of a column.
For example the table:
Header:
Code
Description
Is related to the table Detail via Code:
Detail:
Code
IsGood
such that a change on the field Code of a record in Header requires a change on the field Code of a record in Detail.
Example Data for Header Table:
|
Code |
Description |
|
a |
A Description |
|
b |
B Description |
|
c |
C Description |
|
d |
D Description |
|
Code |
IsGood |
|
a |
1 |
|
a |
2 |
|
a |
1 |
|
a |
3 |
|
a |
4 |
|
b |
1 |
|
c |
1 |
We can see from this example, that if the Header record whose code is changed from “a” into say “t”, then there are five additional record changes that need to happen in the Detail table, for a total of 6 database changes needed.
If Detail is hundreds of records all relating to a Header record via code, then hundrends of record changes need to be propagated thru the database (in the Detail table and any others that may use Code from Header as relational information). This can definately effect the speed at which an agent may respond to a transaction, and can cause additional work on the database manager side that propagates into disk writes and reads and we know how those can slow things down.
So the way to reduce the number of changes is by implementing something called a surrogate key. By adding an integer field into the tables:
Header
Code
HeaderSurrogate
Description
Detail
HeaderSurrogate
IsGood
The relation becomes based on the Surrogate key. The data for the surrogate can come from a database sequence named for that particular relation, such as “headersurrkey.” The database then looks like this:
Example Data for Header Table:
|
Code |
Description |
HeaderSurrogate |
|
a |
A Description |
1 |
|
b |
B Description |
2 |
|
c |
C Description |
3 |
|
d |
D Description |
4 |
|
HeaderSurrogate |
IsGood |
|
1 |
1 |
|
1 |
2 |
|
1 |
1 |
|
1 |
3 |
|
1 |
4 |
|
2 |
1 |
|
3 |
1 |
We can then use the surrogate key to relate by and not the code. So a change of the field code in the table “Header” from an “a” to a “t” will require only one record change, the Header record and none of the Detail records. They will be implicitly changed by the relation back into the Header record by the HeaderSurrogate field.
One the outset, it may appear that some additional coding may be required to find tables that could be related to the Detail record, but by making these records also relate by the surrogate key, this is removed.
FIND Header WHERE
HEADER.Code = “a”
NO-LOCK NO-ERROR.
FOR EACH Detail WHERE
Detail.HeaderSurrogate = Header.HeaderSurrogate ...
FOR EACH CreditDetail WHERE
CreditDetail.HeaderSurrogate = Detail.HeaderSurrogate AND
CreditDetail.IsTax = ....
/* Since Code is no longer in CreditDetail, need to */
/* translate for the user. */
DISPLAY Header.Code CreditDetail.Qty ....
END. /* FOR EACH CreditDetail */
END. /* FOR EACH Detail */
In addition, the use of surrogate keys may be able to reduce the number of columns needed in a table to create a relation. This is in the case of records that are directly related to other records that need two or more columns to be related.
An example across three tables of fields (a, b, c), (a, b, d) and (a, b, e) would be:
|
a |
b |
c |
|
1 |
1 |
t1 |
|
2 |
1 |
t2 |
|
1 |
2 |
t3 |
|
a |
b |
d |
|
1 |
1 |
d1 |
|
2 |
1 |
d2 |
|
1 |
2 |
d3 |
|
a |
b |
e |
|
1 |
1 |
e1 |
|
2 |
1 |
e2 |
|
1 |
2 |
e3 |
By making the table of (a, b, c) the relational header, one can set up a surrogate key, s, for the relations (a, b) on the other tables, with a single column, transforming the tables into:
|
a |
b |
c |
s |
|
1 |
1 |
t1 |
1 |
|
2 |
1 |
t2 |
2 |
|
1 |
2 |
t3 |
3 |
|
s |
d |
|
1 |
d1 |
|
2 |
d2 |
|
3 |
d3 |
|
s |
e |
|
1 |
e1 |
|
2 |
e2 |
|
3 |
e3 |
So in effect, we have removed one column of data the database needs to store, and potentially index (as indices are on the relational fields most of the time!) These space and time savings can be brought across multiple tables if the relation described in the surrogate key is used in multiple tables.
The con to this, is on the outset, it appears the database is heavily de-normalized. There is still some commotion among the people I know if this truthfully is de-normailizing the database architecture or not, as there still are pure relations involved, just at a more abstracted level.[24]
Also, the number of records in a table is limited to the largest integer Progress is capable of generating and storing. So it’s use may be limited if you are expecting the table to contain more than 2 billion (that’s US billions or 2 x 109 ) records. Using Decimal can make the number of records reach into 50 digits according to Progress Limits.
In addition, additional coding may be needed to translate a code the user may enter into the surrogate key by finding the appropriate header record. A small price to pay in large databases.
If the relation is unique, the surrogate key should be unique. If the relation is not unique, then a buffer find may be required to get the original surrogate key value for that combination from a previous CREATE for a new CREATE or MODIFY of a record using that combination.
Setting up a security algorithm:
For security, there needs to be four levels of access.
The following diagram describes the relations visually.
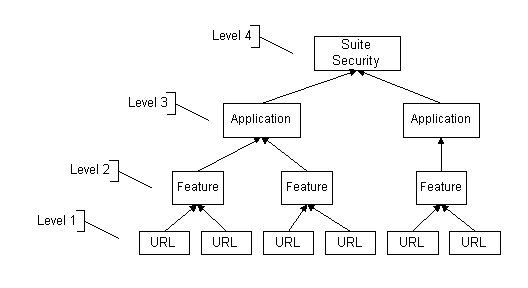
At the lowest level called 1, is the URL. This would be each and every web page we want to handle with the security feature. This level answers if someone bookmarks or attempts to enter the URL into the browser, whether or not if they have any business in the URL.
At the next level called 2, we group sets of URLs into features to handle those sequences of screens that make up some peice of functionallity in the application. These features within a given application can have security set for various users, so as those users can have access to all the URLs in that feature. Some users may have access to a feature (that is actually a collection of URLS) or they may not have access to the feature. However, one set of users could have access to another set of URLs thru a different Feature, thereby giving the application some security over who can go into what feature within the application.
Additional resistance to users accessing an URL can be added at a higher level named 3, by collecting features (which are a collection of URLS) into applications. Access to wide sets of URLs can be denied to a user if they do not have access to the application or any of the lower levels. Applications are made up of features, which in turn are made up of URLs, and any access given to them in the lower levels will give them access to that level and below of URLs in this scheme of doing things.
Finally, determining the applications available to the User can be stored at the top level called 4.
The following describe the basic tables and fields needed to make the above. They do not provide space for naming urls, features, applicactions or suites. They concentrate on grouping elements as described above. Implementors will probably want to add additional information or relations to additional information, such a feature description, application description, and suite description for appearing on a menu of some sort to the user.
TABLE: User
FeatureCode integer Relates to Feature.FeatureCode
URLData character
UserAllowed character
INDEX: Key – URLData, UserAllowed
TABLE: Feature
FeatureCode integer
ApplicationCode integer Relates to Application.ApplicationCode
UserAllowed character
INDEX: Key – FeatureCode, UserAllowed
TABLE: Application
ApplicationCode integer
Suite Code integer Relates to SuiteCode
UserAllowed character
INDEX: Key – ApplicationCode, UserAllowed
TABLE: Suite
SuiteCode integer
UserAllowed character
INDEX: Key – SuiteCode, UserAllowed
The algorithm to check user access would be:
First would be a set of inputes. The data needed are the URL visited, which can be the base name of the URL. It should match what the page would call itself. Also needed would be the visitors name. Right now, that would probably be coming from a cookie. More on that later on in this section.
INPUT URLVisited
INPUT UserName
The first step is to find a level 1 record that would show the given user has access to the URL. If a record with the URL and the user name shows up, then they definately have access to the URL. If not, then we will need to move up the ladder to the next level to determine if they have been given access at that point.
Find URL
where URLValue = URLVisited
and UserAllowed = UserName
if available, allow access
If that original record is not found, then we will need to see if we can find a record with the URL and what feature that URL is a part of. Once that is establised we can then move up to the feature records with the correct feature code. If we cannot find such a record, then the URL probably is not in the security system, and the default in this algorithm is to deny access. Others may want to default to allowing access.
Find URL
where URLValue = URLVisited
if not available, deny access.
Now that we have a URL record that matches the URL visited and the feature that URL is a part of, we can move up and attempt to find a Feature record with the user’s name on it and a feature code matching the feature that URL is a part of.
Find Feature
where UserAllowed = UserName
and Feature.FeatureCode = URL.FeatureCode
If available, allow access
When we cannot find a feature with the user’s name on it, we then need to again move up a level by attempting to find a Feature by the URL’s feature code. Then use that record to find out what Application that Feature is a member of. If no such Feature can be found, then simply deny access.
Find Feature
where Feature.FeatureCode = URL.FeatureCode
if not available, deny access.
Once a Feature record is found, we can use it’s ApplicationCode to locate the Application Record that might be available with the user’s id on it. If such a record exists, then we can allow the user access to the full set of features under the application, as well the full set of urls under that applications’s features.
Find Application
where Application.UserAllowed = UserName
and Application.FeatureCode = Feature.ApplicationCode
If available, allow access
Again if we cannot find the user at the application level, we need to find out what suite the application is under, and if the user has access to the full suite of applications based on an entry in the Suite table.
Find Application
where Application.FeatureCode = Feature.ApplicationCode
if not available, deny access.
Find Suite
where Suite.SuiteCode = Application.SuiteCode
and UserAllowed = UserName.
if available, allow access.
else deny acess.
To run thru a sample:
URL
|
URL |
FeatureCode |
UserAllowed |
|
inp_order |
1 |
scottauge |
Feature
|
FeatureCode |
ApplicationCode |
UserAllowed |
|
1 |
2 |
markrigney |
Application
|
ApplicationCode |
SuiteCode |
UserAllowed |
|
2 |
1 |
mikeemmons |
Lets explore what happens when scottauge tries to access the URL inp_order.
The algorithm attempts to find an URL record with scottauge and the URL. In this example data, we see such a record exists, and so the user scottauge would be allowed into the page.
When markrigney attempts to access URL inp_order, we can see that no such URL record exists with his name on it, so we need to start moving up levels. The algorithm would attempt to find the feature the URL is a member is, in this case 1. Then it would access a feature record with the name markrigney on it, and would allow access to the user.
The user mikeemmons would go thru three such jumps before being allowed access by the algorithm.
If we had a user john doe, which is not mentioned in any of the records, the algorithm would deny john doe access to the page.
This algorithm should be run before any HTML is sent to the browser. This way a RUN statement can be performed that may output another HTML page (like “your not authorized to use this part of the web application.”) To do this effectively, the OUTPUT-HEADERS internal procedure should be used.
The E4GL method’s OUTPUT-HEADERS internal procedure
Using the E4GL method, a special internal procedure is run before any of the main program is executed. By making a listing of the program, one can see what the architecture of the application truely is[25], compared to what one might think it is simply by looking at the coding provided by the application’s programmer.
Before any output is sent to the browser, this program is executed. Inside this program, you may want to put your security algorithms and definately your cookie setting code, as strange things will appear in the browser after the <content text/html> tag is put out (an automatic thing).
In my programs, security is usually always implemented, so I make an include file:
/* security.i include file */
DEFINE OUTPUT-HEADERS:
/* some security based stuff */
/* allow the application programmer to create a local-output-header */
/* to be run after the security is set. */
IF SESSION:GET-SIGNATURE(“local-output-headers”) BEGINS “PROCEDURE” THEN RUN local-output-header.
END. /* OUTPUT-HEADERS */
Javascript for active and inactive fields:
<html>
<head>
<title>New Page 1</title>
<meta name="GENERATOR" content="Microsoft FrontPage 3.0 Sucks">
</head>
<script language="javascript">
// Explore how to make fields active and inactive
// Explore how to determine if fields were changed
// General Theory of Operation:
// Have a set of rules to set varibles describing "activeness" for each input object. Basically,
// onchange()s on input objects will be used to set varibles to describe the "activeness" of other input
// objects. Those objects will have onfocus()s to determine if the user can enter data or
// not.
// Use a set of varibles to determine if an input object should be active,
// initially all input items are active.
var abutton = true;
var aselect = true;
var aradio = true;
var acheckbox = true;
var atexted = true;
var atext = true;
// Have a set of rules to determine if the object is active. Each object
// should have a onfocus() event handler attached to it, to call into this
// function to determine if the input item is active. If not active, blur will
// be applied.
// This is a general function, from here, individual functions determine the activeness
// of an input object. This is so all input objects have one place to go to determine
// activeness. If the object does not have it's activeness controlled, then return
// true at all times.
function isactive (objectptr) {
if (objectptr.name == "button") {
if (abutton == false) objectptr.blur();
}
else
if (objectptr.name == "select") {
if (aselect == false) objectptr.blur();
}
else
if (objectptr.name == "checkbox") {
if (acheckbox == false) objectptr.blur();
}
else
if (objectptr.name == "texted") {
if (atexted == false) objectptr.blur();
}
else
if (objectptr.name == "text") {
if (atext == false) objectptr.blur();
}
return true;
} // isactive()
// This function actually applies rules to if an input object should be
// active or not. This is done by calling from the onchange handler on
// each input object.
function setactive (objectptr) {
alert (objectptr.name);
alert (objectptr.value);
// If the object is the text box, then make the text editor box
// inactive.
if (objectptr.name == "checkbox") {
if (objectptr.checked)
atext = false;
else
atext = true;
alert("set atext to " + atext);
} // text box was populated
} // setactive()
</script>
<body>
<form method="POST">
<p><input type="button" value="Button" name="button" onfocus="isactive(this)"></p>
<p><select name="select" size="1" onfocus="isactive(this)" onchange="setactive(this)">
</select></p>
<p><input type="radio" value="radio" checked name="radio" onfocus="isactive(this)"
onclick="setactive(this)"></p>
<p><input type="checkbox" name="checkbox" value="checked" onfocus="isactive(this)"
onclick="setactive(this)"></p>
<p><textarea rows="2" name="texted" cols="20" onfocus="isactive(this)"
onchange="setactive(this)"></textarea></p>
<p><input type="text" name="text" size="20" onfocus="isactive(this)"
onchange="setactive(this)"></p>
<p> </p>
</form>
</body>
</html>
Javascript for required fields:
<html>
<head>
<title>New Page 1</title>
<meta name="GENERATOR" content="Microsoft FrontPage 3.0">
</head>
<script language="javascript">
// Determine that required fields in the form have been entered
// Function to call on the submit of the form. This should be mentioned
// in the FORM tags event handle onsubmit()
function valreqfld (formptr) {
var noerror = true;
var errormsg = "";
// Here we check if required fields have been entered.
if (formptr.T1.value == "") {
errormsg = errormsg + "T1 is required entry\n";
noerror = false;
}
if (formptr.T3.value == "") {
errormsg = errormsg + "T3 is required entry\n";
noerror = false;
}
if (! noerror) alert (errormsg);
return noerror;
}
</script>
<body>
<form method="POST" name="test" onsubmit="valreqfld (test)">
<p><input type="text" name="T1" size="20"></p>
<p><input type="text" name="T2" size="20"></p>
<p><input type="text" name="T3" size="20"></p>
<p><input type="text" name="T4" size="20"></p>
<p><input type="submit" value="Submit" name="B1"><input type="reset" value="Reset"
name="B2"></p>
</form>
</body>
</html>
Javascript for client level calculations:
<html>
<head>
<title>New Page 1</title>
<meta name="GENERATOR" content="Microsoft FrontPage 3.0">
</head>
<body>
<form method="POST" name="calc">
<script language="javascript">
// How to set up a calculation between fields and how to make the sum
// fields "read only"
// Note that the function is in the form object which contains the input
// objects that will be used to calculate with.
function calculate () {
document.calc.t3.value = Number(document.calc.t1.value)
+ Number(document.calc.t2.value);
} // calculate
</script>
<p><input type="text" name="t1" size="20"
onchange="calculate()"></p>
<p><input type="text" name="t2" size="20" onchange="calculate()"></p>
<p><input type="text" name="t3" size="20" onfocus="this.blur()"></p>
<p><input type="submit" value="Submit" name="B1"><input type="reset" value="Reset"
name="B2"></p>
</form>
</body>
</html>
Where to get more information
Since the web has become so hot, there are new books and new technologies out there all the time. So I will skip over the book category, as one can glean thru them at the book store (or the web site!)
I will say, you will want a book on HTML that provides a reference section, because once you understand it, you will be more interested in “what was that again” instead of surfing thru tutorial content. Same goes for Javascript, Java, and VB Script.
Online:
Though I like my tutorial kinds of books to be hardcopy, I prefer my reference types of books to be on-line.
Netscape keeps developers informed about the abilities of it’s browsers at this site. Usually one can find the latest javascript reference and HTML reference for their browsers in HTML archived within a ZIP file for download. At the time of this writing, it was free.
Microsoft also keeps documents on HTML, VBScript, and Javascript at it’s site. At the time of this writing, the user would need to register with Microsoft to access this information.
Web application development can be handled by the company I helped found: Auge, Emmons, & Ziola, Inc.
http://www.amduus.com
I can be reached at sauge@amduus.com or thru the main Progress E-Mail Group .
[1] The screen is controlled by the browser, and not by any of Progress’ web tools, so to make the browser display properly, the programmer will need to be familiar with HTML, the language the browser uses to render the output to the screen.
[2] See www.gartnergroup.com as well other advisory organizations.
[3] How much memory have you bought for your machines so people can log in and not use that memory continously while away at a meeting or a brief brain break?
[4] HTML is Hyper-Text Markup Language. A browser can be thought of as a visual printer. Just as a printer uses special codes to define where characters should be bolded and where they should be italized, a browser uses this special language to explain how a page should be rendered on the screen.
[5] Oracle, Informix, Symantec, ODBC, SQL Server, etc.
[6] Hence, if the webserver is on the internet, you will need a domain name server registered with the internic that the internet root servers can use to find the IP address of your machine with.
[7] Generally this is port 80. For processes not running under root authority, the port 8080 is common.
[8] Depending on the web server used, the options of an NSAPI and ISAPI interface could be used.
[9] These distrinctions are noted usually in a web server configuration file that is modified and used by the web server on start up. For example, Lotus Dominoe uses /etc/httpd.conf or a web based configuration can be performed. Lotus Dominoe, Netscape Fast Track, and Microsoft IIS all have web based configuration available for the server to be set up. See the server operations guide for more information.
[10] Part of the URL after the cgi program name
[11] I usually put it in the same place as the *.pf file used by the agents to connect to the database for the given application. This way everything is in one spot for a given application.
[12] Many of these ideas are heavily borrowing ideas on Software Diagraming developed in the book ___, by ____ ISBN _____. Their ideas were modified to meet the needs of web programming which was not present at the time the book was written.
[13] A method in javascript that allows the same page to be reloaded. Unfortunately if the page was made available from a POST on the action of a form, the hidden fields are lost in some browsers. Using a GET as the action at least encodes all the form fields into the URL instead of thru stdin. See the tips section for more information about this behavior.
[14] My condolences to the programmer responsible for getting the UPDATE EDITING statement to work, as I can imagine it was quite an effort and now is useless in Webspeed.
[15] Javascript and VBScript can also be used to set and read cookie information on a browser, but using javascript and VBScript will give the application user some insight on what is happening inside the application if done thru these languages, as the instructions are transmitted to the browser and a View Source will lay naked the HTML, Javascript, and VBScript code. This may be of concern if you have an internet application as it gives clues about what is happening. The 4GL language elements are never sent to the browser as these are server side instructions.
[16] Of which, none exist to my knowledge, though I have tossed around the idea. Since there is a competing product out there that is made by the actual vendor, that would be the best route to take.
[17] This is actually defined by a proprocessor symbol known as OUT and is referenced by {&OUT} in the source. See your Workshop Programming Guide for more information on preprocessor definitions available.
[18] All this client starting up and shutting down may strike the reader as a lot of overhead. This would be true if the architecture has been like Progress architectures before. In Webspeed the broker and agent processes are already always running – they pretty much just run the program specified outputting the results and then waiting again for a program to be specified.
[19] The ip prefix identifies the program as being an internal procedure to the source procedure.
[20] It is recommended that local varibles be used to store the values of form fields. This way they can be conveniently checked and validated before assignment to the database record, which may cause a Progress error – and we know how ugly those are on the screen.
[21] Be sure to remember the mapping of the directory in the URL must be fore thought out as the directory is often hard coded into the application with such items as <IMG SRC=”images/button.gif”> where images would be mapped into /appl/static by the web server. One may not want to mix up icons and maybe one does to have one point of maintenace for marketing graphics guidelines. Just note that this is something to think about.
[22] Set inside the webspeed.cnf file for each broker service defined.
[23] Note that you will want a new wtb for each agents to start up for an application. If an application has a commonly named file, at least one of the agents are going to be confused by it.
[24] My short argument on this, is that since the relation is described by a simple substitution of (a,b) with (s), and that (s) is equivalent to (a,b), that is an onto relationship or one-to-one, then the table is still normalized as s is merely a substitution for the values of a and b. It is really quite mechanical....
[25] There is a great deal of interesting plumbing involved to make the application work in a clean and concise manner.